
Listen to this Article

A new benchmark measuring how well AI coding models generate accessible code shows a sharp divide between leading AI companies.
The AI Model Accessibility Checker, known as AIMAC, released its first round of results in January 2026. It is the first standardized benchmark designed to evaluate how AI coding models perform against accessibility requirements for people with disabilities. AIMAC is a joint project of the GAAD Foundation and ServiceNow. It was co-created by Joe Devon, chair of the GAAD Foundation, and Eamon McErlean, vice-president and global head of digital accessibility and globalization at ServiceNow.

The benchmark is designed to give AI companies clear feedback and help organizations understand which AI coding models are more likely to support accessible digital products from the start.
AIMAC’s findings show that OpenAI leads the field by a wide margin. Google and Anthropic trail behind, with Google’s newest flagship model ranking last.
They tested 36 AI coding models from major providers. Each model was evaluated on how well it generated accessible code, including proper labels, color contrast and form controls that meet established accessibility standards. OpenAI claimed the top four positions in the ranking positioning them as the clear leader in accessible code generation among major AI developers.
GPT 5.2 Pro
GPT 5.2
GPT 5.1 Codex
GPT 5.1 Codex Mini
Anthropic showed mixed performance. Claude Haiku 4.5, the company’s smallest model, placed 10th. Claude Sonnet 4.5 ranked 19th. Claude Opus 4.5, Anthropic’s flagship and most expensive model, finished 24th. It recorded 810 total accessibility violations.
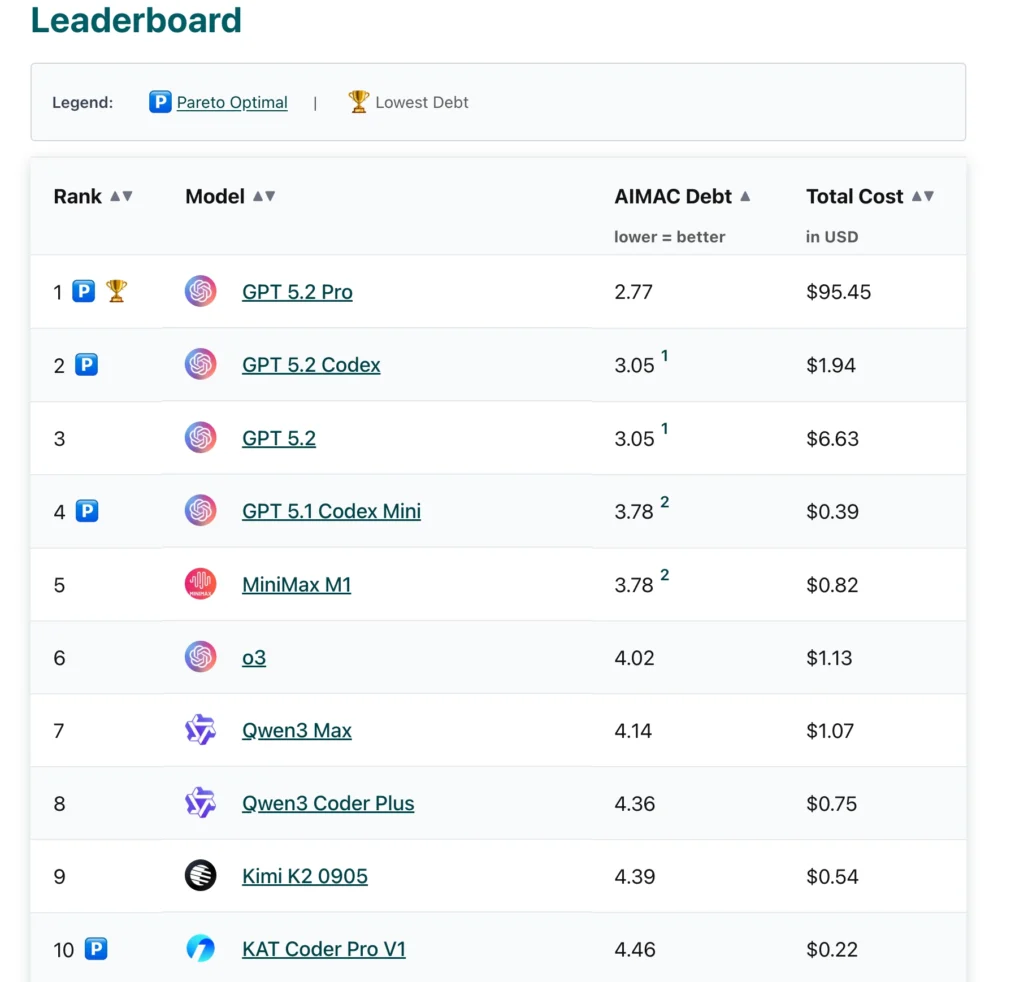
Google performed worst overall. Gemini Pro 3.0 ranked last out of all 36 models tested. The model generated hundreds of accessibility failures, including 286 color contrast violations, 47 unlabeled links and 20 form select elements without accessible names. Google’s lighter Gemini models placed 20th and 22nd.
The results were especially striking given that Gemini Pro 3.0 is Google’s newest flagship release. The outcome highlights a significant gap between technical performance and accessibility readiness.
Joe Devon, co-creator of AIMAC, said the goal of the benchmark is accountability.
“Our mission with creating the AI Model Accessibility Checker is to provide feedback to the foundation AI model companies as to how accessible their large language models are,” said Devon. “We also want to inform corporate IT and accessibility departments which AI models to pick if they want to improve the accessibility of websites and products designed with AI-generated code.”
“Accessibility must be treated as a first-class requirement, not an afterthought,” McErlean said. “With AIMAC, we are meeting AI researchers where they are and challenging them against defined accessibility benchmarks.”
The stakes are high. Industry research suggests that about 95 per cent of the web remains inaccessible to people with disabilities. As AI coding tools move from experimentation into production environments, the accessibility quality of their output could shape the future of the web.
“It is our hope that these companies will take AIMAC’s feedback up the chain and make the necessary adjustments,” Devon said.
AIMAC’s creators hope the benchmark will push AI companies to improve. This benchmark matters because AI is now writing real software. These tools are no longer experimental. They are being used to build websites, apps and digital services at scale.
When accessibility is missing from AI-generated code, those problems multiply fast. Poor colour contrast, missing labels and inaccessible forms get copied again and again. What used to be a single developer mistake can now become a system-wide problem.
Devon is also co-founder of Global Accessibility Awareness Day. He said OpenAI’s strong showing was not unexpected.
“We were not surprised to see OpenAI do so well since they were launch partners with Be My Eyes,” he said.
Google’s performance, however, stood out. “We were surprised to see Google’s disappointing results,” Devon said. “Their flagship model came in last.”
He added that Anthropic also fell short of expectations given the cost and positioning of its models.
Eamon McErlean said the benchmark arrives at a critical moment.
“There are over one billion people in the world living with disabilities, and technology has advanced without fully considering them,” he said. “We are trying to change this pattern at the start of this new wave of AI coding models.”
He said accessibility needs to be embedded from the beginning.
“Accessibility must be treated as a first-class requirement, not an afterthought,” McErlean said. “With AIMAC, we are meeting AI researchers where they are and challenging them against defined accessibility benchmarks.”
The stakes are high. Industry research suggests that about 95 per cent of the web remains inaccessible to people with disabilities. As AI coding tools move from experimentation into production environments, the accessibility quality of their output could shape the future of the web.
“It is our hope that these companies will take AIMAC’s feedback up the chain and make the necessary adjustments,” Devon said.
AIMAC’s creators hope the benchmark will push AI companies to improve. This benchmark matters because AI is now writing real software. These tools are no longer experimental. They are being used to build websites, apps and digital services at scale.
When accessibility is missing from AI-generated code, those problems multiply fast. Poor colour contrast, missing labels and inaccessible forms get copied again and again. What used to be a single developer mistake can now become a system-wide problem.
For the 1.3 billion people worldwide living with disabilities, this moment is pivotal. The web is already largely inaccessible. AI could help fix that by making accessibility the default. It could also make things worse if these gaps are ignored.
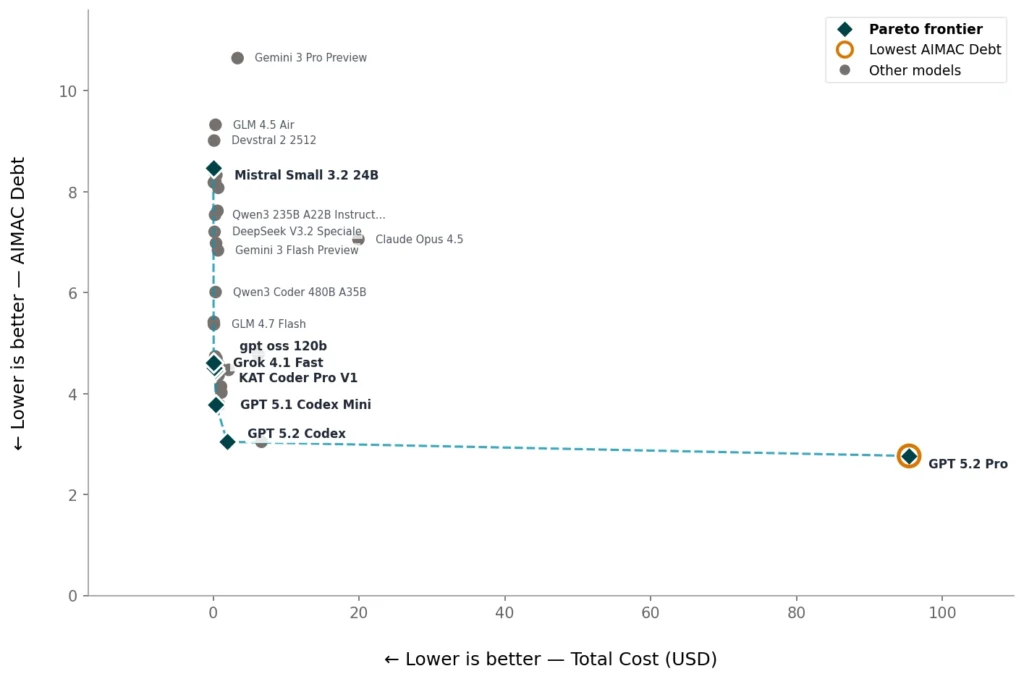
The AIMAC results show that accessible code is possible today. Some models do it well. Others clearly do not. That difference matters as organizations choose which AI tools to trust.
For companies using AI coding assistants, model choice now affects real people. Picking the wrong model can increase barriers and future cleanup costs. Picking the right one can raise accessibility from the start.
As AI reshapes how the web gets built, benchmarks like AIMAC help show whether technology is opening doors or closing them.
The full leaderboard and testing methodology are available at AIMAC.ai.